Caucus V1: Cursor Background Agents and a Multi-Agent Workflow That Actually Loops
I’ve been using Cursor 3 more over the last week or so because it makes it easy to move between models, and Cursor’s Composer 2 has been producing good results for me. That’s become more important because Opus 4.6 has gotten noticeably worse for me in Zabriskie. Work that used to feel routine, like straightforward file edits or basic follow-through on multi-step changes, now takes forever across multiple prompts, comes back half-finished, or fails basic CI checks. The model that was my primary tool for two months of shipping Zabriskie has started struggling with things it used to do in one pass.
That matters here because this project has become, whether I intended it or not, a study in what happens when the model is not consistently reliable. If the agent can’t be trusted to do basic work cleanly every time, then the surrounding system has to take on more of that burden by preserving state between steps, recovering from predictable failures, and making it obvious what happened when something goes wrong.
The last few posts have been converging on this from different directions. Multi-Agent Systems Have a Distributed Systems Problem is where I said most clearly that these systems need real coordination machinery, not just role descriptions and prompt choreography. Software Engineering Is Becoming Civil Engineering and The Feature That Has Never Worked pushed me toward the more practical version of that same conclusion: if the models are inconsistent, the surrounding system has to get stronger.
So this post is not just adjacent to that earlier multi-agent piece. It’s the first concrete version of the system I was pointing at there. In that post, the argument was that multi-agent software systems need real coordination machinery instead of roleplay and prompt choreography. Caucus V1 is rev 1 of that vision. It’s the first pass at a runtime that actually tries to encode those ideas into the workflow itself.
This week I built that first version. It’s called Caucus, and for the first time I have a multi-agent loop that actually completes end to end.
Why Cursor Agents Matter Here
Part of what makes this worth building now is that Cursor’s background agents are not just chat windows with long prompts. They run in the cloud on actual computers. They can check out code, make changes, open pull requests, wait for CI to finish, respond to failures, and keep working while I’m not sitting there driving every keystroke.
That changes the shape of the problem. If an agent can only draft code in a text box, then “multi-agent” mostly means multiple role descriptions. If an agent can actually live inside a software workflow, then it can do the things a real teammate would do. It can implement a change, open a PR, wait for checks, fix what failed, run the app, and produce evidence that the feature works.
That’s the part I think people are still underestimating. These agents are not interesting because they can talk about code. They’re interesting because they can operate on real software artifacts over time.
And the most striking capability is what happens after the code is written. A Cursor background agent can start the application, interact with it, take screenshots of the running UI, and record a video walkthrough demonstrating that the feature actually works. It can attach that evidence to the PR alongside a passing CI build. That’s not “code generation.” That’s a worker producing deliverables with proof.
That is the enabling condition for the version of Caucus I want. Without agents that can actually execute against a repository, run CI, start the app, and produce visual evidence that the change is correct, multi-agent coordination is mostly theater. My vision is not a cast of roleplaying agents debating architecture in a transcript. It’s a system of agents that can take responsibility for different parts of a real development loop, with the runtime coordinating their work and preserving enough structure that the loop remains legible.
What Caucus V1 Actually Is
Right now, Caucus V1 is a very small system with a very specific job. It coordinates a fixed set of background agents around a pull request lifecycle.
In practice, that means one agent implements code changes and opens or updates a PR, another agent reviews that PR and either approves it or requests changes, and the runtime keeps looping until the PR is approved or a safety cap is hit. That loop is the whole point. Most multi-agent demos are linear: agent A hands off to agent B, and the workflow is done. Caucus V1 has a cycle in its DAG. The reviewer can send work back to the implementer, and the implementer can re-enter the same PR and refine it.
What makes that cycle possible is the causal history that the runtime carries forward between stages. The implementation agent doesn’t just receive a generic task the second time around. It knows it’s refining a PR based on review feedback because the handoff tells it so. It knows how many times each role has acted. It knows what the reviewer said. It knows it’s on its second or third pass. That history is what lets the agent infer what the next action should be, rather than starting over from scratch every time it’s invoked.
That may not sound ambitious, but I think it’s more honest than most multi-agent demos. The hard part is not getting two agents to say different things in sequence. The hard part is giving the system enough structure that the second and third turns are still meaningfully connected to the first one.
The Most Important Part Is The Tiny Vector Clock
The most interesting idea in V1 is probably also the smallest one. Each stage handoff carries an actorClock, which is just a dictionary counting how many times each role has acted so far. If the payload says {\"implement\": 2, \"review\": 1}, that means the implementer has already acted twice and the reviewer once.
That is obviously not a full causal history. It is not a general solution to the coordination problem. But it is a real step toward the kind of machinery I was arguing for in Multi-Agent Systems Have a Distributed Systems Problem. It’s a tiny version of the vector clock idea: enough ordering information for an agent to know where it is in the workflow without pretending the whole world can be reconstructed from prompt text alone.
In practice, that matters because the implementer should behave differently on the first pass than it does on a remediation pass. On the first pass, it’s trying to complete the task. On the second or third pass, it’s trying to interpret review feedback and update the same PR without losing the thread. actorClock gives the runtime just enough structure to express that difference.
This is what I mean when I say Caucus V1 is rev 1 of that earlier vision. I’m not claiming to have solved multi-agent coordination. I’m saying the runtime is starting to encode some of the right primitives instead of relying entirely on roleplay and prompt choreography.
What We’ve Built So Far
None of this is obvious from product names on a screen, so here is the actual job, then what the UI is for.
The job is to keep two long-lived Cursor background workers alive, one for implementation and one for code review, and to drive them through a loop: implement, review, maybe implement again, until the PR is approved or the loop hits a safety limit. “Caucus” is just the local web UI plus Python code that calls Cursor’s agent API, tracks handoffs, and talks to GitHub when it needs to.
The UI exists so I do not have to remember API details every time. In one row I can type what I want done (for example a small change in the repo to exercise the loop). Separately, there is a control whose only job is to provision those two cloud workers through Cursor (implementation session and review session). There is another control whose only job is to run one traversal of the loop against the workers that are already provisioned: send the task to the implementer, wait for structured output, send context to the reviewer, branch on approve versus request changes, repeat. The labels on my build say “Start” and “Run minimal cycle”; the point is the separation, not the wording. There is also stop, and a path for “I already have a PR, skip straight to review and remediation” for faster debugging.
A few properties of that setup feel foundational:
-
No silent substitution of workers. The run-the-loop action refuses to allocate fresh agents if the pair was never provisioned or if a session died. It fails loudly instead of pretending continuity. The assumption is that a multi-agent workflow only deserves the name if the same identifiable Cursor runs carry context across rounds. Otherwise it is just a string of unrelated one-off jobs.
-
Structured handoff between the two roles. After each side finishes, it emits JSON the runtime can parse (for example
prUrl,reviewDecision,commentUrls, and theactorClockI mentioned earlier). A small orchestrator in the Caucus code reads those fields; it does not scrape adjectives out of the model’s closing paragraph. -
Remediation tied to GitHub, not to chat memory. When review requests changes and implementation runs again, the orchestrator pulls live comments and reviews with
gh apiand bakes that into the next task. The source of truth is the PR thread. -
The runtime can patch around a flaky side. If the review worker cannot post to GitHub, the orchestrator can post from the machine running Caucus. If the implementation worker never emits a tidy PR URL, the orchestrator can still recover the link from the transcript. Reliability is allowed to live outside any single model reply.
Why The Dashboard Matters
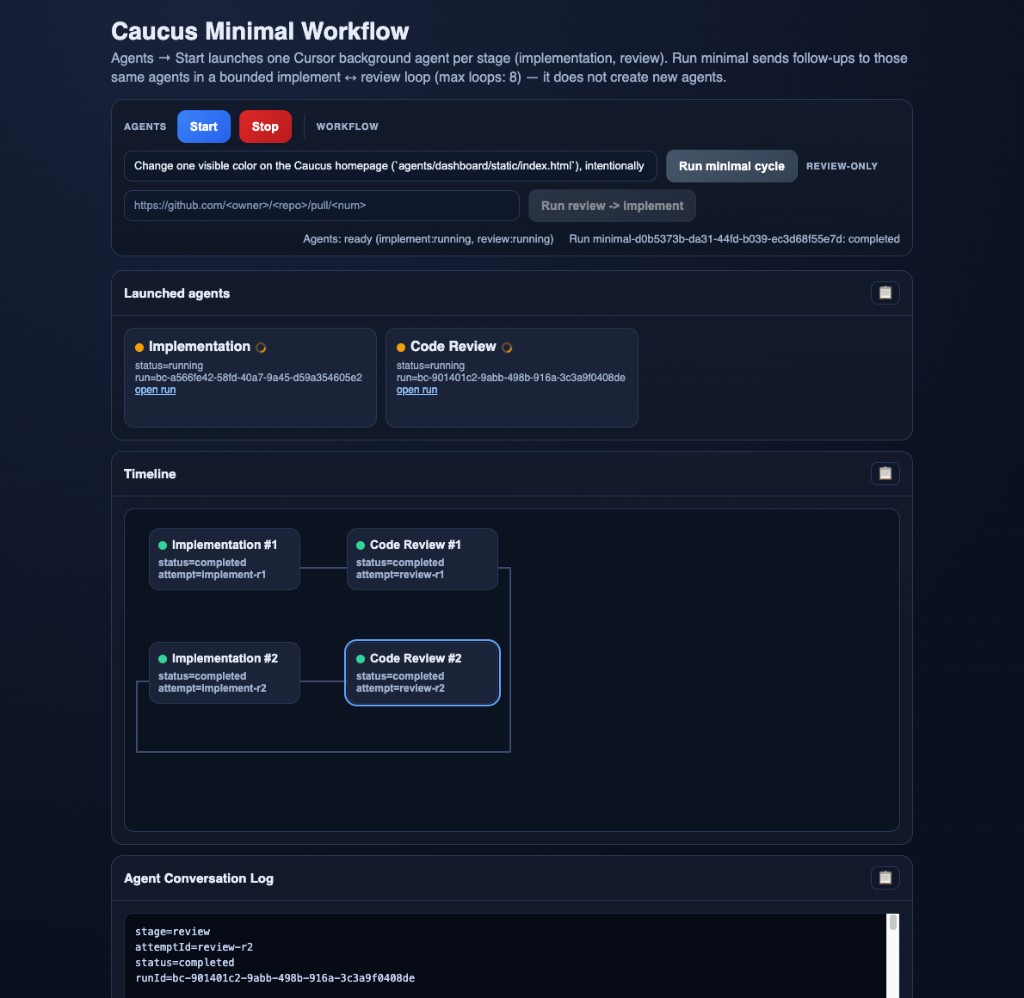
The screenshot is there because the page is doing real work, not decoration. Reading top to bottom: the text field is the task I am asking the implementation side to perform. The blue and red actions are allocate versus tear down the two Cursor background sessions (implementation and review). Next to that is the action that runs the loop once through those sessions, using that task. Off to the side there is an optional alternate path where I paste an existing pull request URL if I only want to exercise “review said no, fix it again” without a fresh implementation pass. Below that, two cards show whether each Cursor run is actually alive and link out to the run in Cursor’s UI if I need the full transcript. The strip in the middle is the graph of attempts in order (first implementation, first review, second implementation, and so on), so I can see the cycle without inferring it from logs. The panel at the bottom is the per-attempt trace: which stage, which handoff id, whether it finished, and the run id to correlate with Cursor.
One thing I did not appreciate at the beginning is how much that surface is part of the runtime, not a thin skin on top.
For a multi-round system, observability is not optional. If implementation and review can each happen multiple times, you need attempt history as a first-class thing: which round failed, what the handoff contained, what the orchestrator decided, and whether you are stuck because a worker died, because the run is waiting, or because a payload was malformed.
So the UI is doing what a control panel for a distributed job should do. It maps the DAG, separates “are the workers up” from “what did the last loop try,” and streams enough detail to replay decisions. If you cannot see the cycle, you cannot debug the cycle. If you cannot debug it, you do not have a system yet, you have a toy.
Where This Is Going
V1 is intentionally narrow. It is a workflow kernel, not a full multi-agent platform.
It still doesn’t handle concurrent agents modifying the same branch. It still doesn’t validate stage outputs beyond basic structure. It still trusts a reviewer approval more than it probably should. It still doesn’t do fault injection at stage boundaries, which is where I think the next really interesting work is. What happens when the handoff payload is malformed? What happens when an agent returns stale state from an earlier run? What happens when two different remediation loops race?
Those are the questions that make the distributed systems framing feel real to me. They’re also why I don’t want this post to read like a launch announcement. Caucus V1 is important to me not because it’s complete, but because it’s the first version that feels like a concrete system rather than an idea with role prompts attached to it.
That’s also why I wanted to write about it now. In the earlier multi-agent post, the argument was that we needed more than role decomposition. We needed actual coordination machinery. This is the first concrete version of that claim. It’s small, but it’s real. It carries state forward. It loops. It exposes failure. It gives me one tiny vector-clock-shaped primitive to build on. And it makes the next step legible.
That’s enough for V1.